
Navigating Deep Learning to Improve ADAS

Deep Learning & ADAS
Real-time decision making at the edge drives progress in autonomous vehicle systems
The automotive industry is leveraging big data more than ever before. As a range of sensors and other equipment advance the Five Levels of ADAS, autonomous vehicles are better able to navigate, steer clear of obstacles, and follow road marker instructions. AI is most certainly driving these improvements. Deep learning training and deep learning inference models – deployed at the edge – are absolutely essential to ongoing innovation and flawless autonomous performance. But, to take full advantage of this level of intelligence, specialized hardware is necessary. Hardened systems, stocked to the hilt with high-speed solid-state data storage, GPU and CPU processing, robust connectivity, hardware-based security and much more, deliver the performance required to optimize massive amounts of data.
Software-based deep learning functions and ruggedized hardware work together to aggregate, store, and apply real-time data. But what are deep learning training and deep learning inference? And what types of systems can handle the constant barrage of new and refined data? Our article in Autonomous Vehicle Engineering explains the differences and relationship between deep learning training and inference, and how these technologies are best applied for smarter, safer, and more autonomous vehicles.
Overview
Automotive ‘big data’ is here. The immense scope of data generated by automated or ADAS-integrated vehicles spans the five SAE levels of autonomous driving, with reliance on high-resolution cameras, radar, lidar, ultrasonic sensors, GPS and other sensors for vehicles to see or perceive their surroundings. Ultimately, this sensory information – massive amounts of data – is used to navigate, avoid obstacles and read road markers necessary for safe driving.
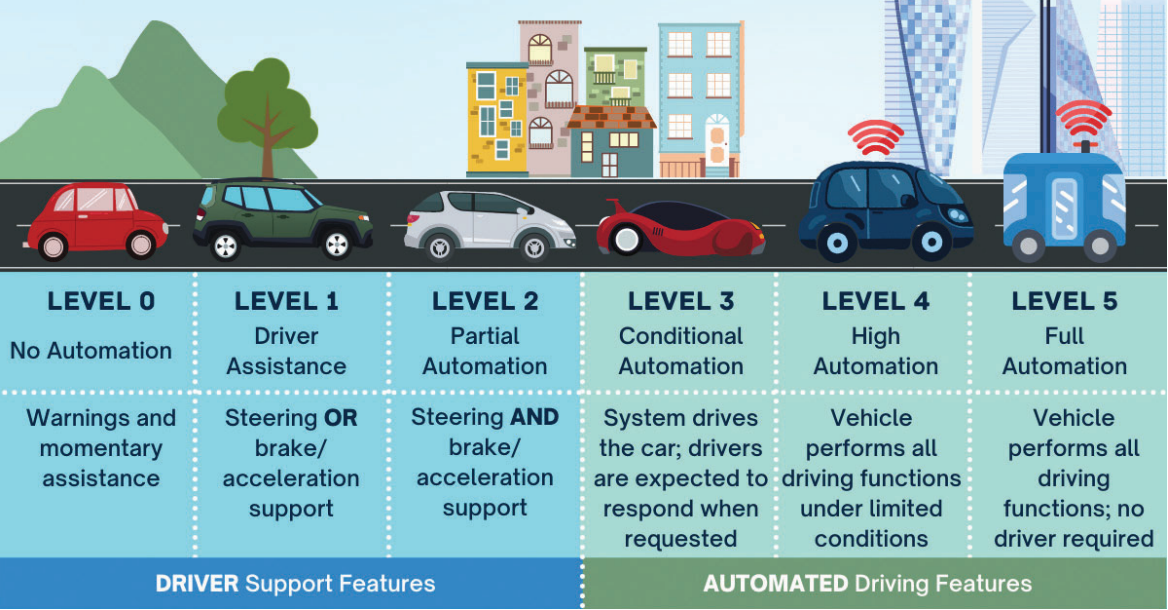
Artificial intelligence (AI) is at the heart of these operations, grounded in software algorithms and fueled by deep-learning training and deep-learning inference models that are essential to faultless performance. Enabling these vital and instantaneous processes requires AI algorithms to be trained and then deployed on-vehicle. It’s a process that has developers tapping into both sophisticated software design and smart hardware strategies to protect vehicle performance that could be a matter of life or death. While deep-learning training and deep-learning inference may sound like interchangeable terms, each has a very different role to play in systems that keep drivers safe and distinguish OEMs with increasingly intelligent auto features. Deep-learning training employs datasets to teach a deep neural network to complete an AI task, like image or voice recognition. Deep-learning inference is the process of feeding the same network with novel or new data, to predict what that data means based on its training. These data-intensive compute operations require specialized solutions. Systems must feature large amounts of high-speed, solid-state data storage. They also must be hardened for deployment in vehicles that are constantly moving, subject to violent shock and vibration and other harsh environmental factors. Ideal design pairs the software-based functions of deep learning with ruggedized hardware strategies optimized for both edge and cloud processing.
Deep-learning training, explained
Although the most challenging and time-consuming method of creating AI, deep-learning training gives a deep neural network (DNN) its ability to accomplish a task. DNNs, comprised of many layers of interconnected artificial neurons, must learn to perform a particular AI task, such as translating speech to text, image classification, video cataloging, or generating a recommendation system. This is achieved by feeding data to the DNN, which it then uses to predict what the data signifies. For instance, a DNN might be taught how to differentiate three different objects – a dog, a car, and a bicycle. The first step puts together a data set consisting of thousands of images that include dogs, cars, and bikes.The second step feeds the images to the DNN and empowers it to ascertain what the image represents. When an inaccurate prediction is made, the artificial neurons are revised, correcting the error so future inferences are more accurate. In this process, it is likely that the network will better predict the image’s true nature each consecutive time it is presented. The training process continues until the DNN’s predictions meet the desired level of accuracy.

At this point, the trained model is sufficiently prepared to use new images to make predictions. Deep-learning training can be extremely compute-intensive, with billions upon billions of calculations often necessary for training a DNN. The method relies on robust computing power to run calculations quickly. Performed in data centers, deep neural-network training leverages multi-core processors, GPUs, VPUs and other performance accelerators to advance AI workloads with enormous speed and accuracy.
Deep-learning inference
An extension of deep-learning training, deep-learning inference uses a fully trained DNN to make predictions based on new, never-seen-before data closer to where its generated. By feeding new data, such as images, to the network, deep learning inference enables DNN classification of the image. For example, adding to the ‘dog, car, bicycle’ example, new images of these and other objects can be loaded into the DNN allowing image classification. The fully trained DNN now can accurately predict the image’s identity. Once a DNN is fully trained, it can be copied to other devices. DNNs can be extremely large, containing hundreds of layers of artificial neurons and connecting billions of weights. Before it can be deployed, the network must be modified to require less computing power, energy and memory. The result is a slightly less accurate model, but this is offset by its simplification benefits.

Two methods can be deployed to modify the DNN; pruning or quantization. In pruning, a data scientist feeds data to the DNN and observes. Non-firing or rarely firing neurons are identified and removed without causing significant reduction in prediction accuracy. Quantization involves reducing weight precision. For example, a 32-bit floating-point reduced to an 8-bit floating-point creates a small model that consumes fewer compute resources. Both methods have negligible impact on model accuracy. At the same time, the models become much smaller and faster, resulting in less energy use and lower consumption of compute resources.
Making the edge work in ADAS
Deep-learning inference ‘at the edge’ has commonly used a hybrid model in which an edge computer harvests information from a sensor or camera and transmits that information to the cloud. However, latency occurs as data often requires a few seconds to be delivered to the cloud, analyzed, and returned – unacceptable for applications requiring real-time inference analysis or detection. An AV moving at 60 mph (96 km/h) could travel more than 100 feet (30 m) without guidance in just a few seconds. In contrast, purpose-built edge computing devices perform inference analysis in real time for split-second autonomous decision-making. These industrial-grade AI inference computers are designed to endure challenging in-vehicle deployments. Tolerant to a variety of power-input scenarios, including being powered by a vehicle battery, systems are ruggedized for expected exposure to impact, vibration, extreme temperature, dust and other environmental challenges.

With configurable processing power, edge inference computers are capable of running machine learning and deep learning inference analysis at the edge. Performance accelerators including multi-core processors, GPUs, VPUs, TPUs, FPGAs, and NVMe computational storage devices increase capability, especially in modern computer architecture designs. Equipped with a rich I/O, autonomous vehicle data recorders offer ample USB Type-A ports (Gen 3.2 10Gbps), RJ45 and M12 Gigabit Ethernet ports, RJ45 and M12 PoE+ ports, Serial COM ports, and others, enabling connection to the cameras and sensors to data computers.
These characteristics alleviate many of the issues associated with processing deep-learning inference algorithms via the cloud, coupled with unique high performance. For example, GPUs and TPUs accelerate the ability to perform myriad linear algebra computations, enabling the system to parallelize such operations. Rather than the CPU performing AI inference computations, the GPU or TPU – better at performing math computations – tackles the workload, significantly accelerating inference analysis while the CPU focuses on running the rest of the applications and the operating system. Local inference processing also eliminates latency problems and solves internet bandwidth issues related to raw data transmission, particularly large video feeds. Multiple wired and wireless connectivity technologies, such as Gigabit Ethernet, 10 Gigabit Ethernet, Wi-Fi 6, and Cellular 4G LTE allow the system to maintain internet connection in a range of situations. Up-and-coming 5G wireless connectivity expands options even further with its significantly faster data rate, much lower latency, and improved bandwidth. These rich connectivity options enable the offload of mission-critical data to the cloud and accommodate over-the-air updates. In addition, CANBus support empowers the solution to log vehicle data from vehicle buses and networks. Vehicle speed, wheel speed, engine rpm, steering angle and other rich data can be assessed for real-time insight and important information about the vehicle.
Big data, big opportunity
To bring an ever-growing list of automated-driving capabilities to market, ADAS developers have been focused on improving the algorithms that impact features and performance. But specialized hardware is necessary – AI edge-inference computers are the hardened computing solutions developed for this process, built to withstand exposure to dust, debris, shock, vibration and extreme temperatures and designed to collect process, and store a vast amount of data from multiple sources. Amassing data is only step one to fueling ADAS; software development and specialized hardware strategies must work together for smarter, safer, and more highly-automated vehicles.